tech talks
Sign in
Register
Open main menu
Sign in
Register
Filters
1
Tags
Speakers
Events
Sort By
Recommended
Newest First
Oldest First
Title A-Z
Title Z-A
More Filters
Language
(
all
/
none
)
🇬🇧 English
(815)
🇪🇸 Spanish
(11)
🇫🇷 French
(2)
🇳🇱 Dutch
(2)
🇮🇳 Hindi
(2)
🇮🇹 Italian
(1)
🌐 No language set
(135)
Clear All Filters
Popular Topics
react
python
javascript
typescript
ruby-on-rails
ruby
machine-learning
kubernetes
Filters
Tags
Speakers
Events
Sort By
Recommended
Newest First
Oldest First
Title A-Z
Title Z-A
More Filters
Language
(
all
/
none
)
🇬🇧 English
(815)
🇪🇸 Spanish
(11)
🇫🇷 French
(2)
🇳🇱 Dutch
(2)
🇮🇳 Hindi
(2)
🇮🇹 Italian
(1)
🌐 No language set
(135)
Clear All Filters
Popular Topics
react
python
javascript
typescript
ruby-on-rails
ruby
machine-learning
kubernetes
30 min
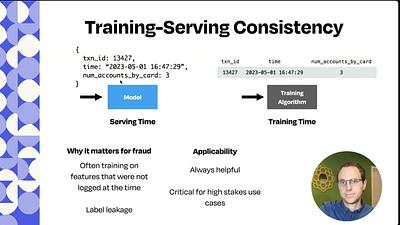
Learning from Extremes: What Fraud-Fighting at Scale Can Teach Us About MLOps Across Domains
MLOps World - MLOps World & Generative AI World 2024
Greg Kuhlmann
fraud-prevention
training-serving-consistency
mlops
machine-learning
real-time-ml
data-modeling
feature-engineering
observability
agile-development
data-pipelines
inference
scalability
5 min
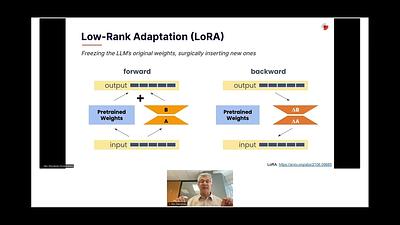
How Do You Scale to Billions of Fine-Tuned LLMs
MLOps World - MLOps World & Generative AI World 2024
James Dbiorin
cuda
batching
llm
large-language-models
fine-tuning
lora
inference
scalability
parameter-efficient-fine-tuning
gpu
mlops
ai
42 min
Efficiently Fine-Tune And Serve Your Own LLMs
MLOps World - MLOps World & Generative AI World 2024
Alex Sherstinsky
llm-fine-tuning
predibase
ludwig
lorax
large-language-models
lora
parameter-efficient-fine-tuning
peft
transformer-models
mistral-7b
model-serving
inference
48 min
Building ML and GenAI Systems with Metaflow
MLOps World - MLOps World & Generative AI World 2024
Ville Tuulos
ai-systems
ml
machine-learning
genai
generative-ai
metaflow
data-engineering
model-training
inference
python
mlops
41 min
Lessons learned from scaling large language models in production
MLOps World - MLOps World & Generative AI World 2024
Matt Squire
ray-serve
large-language-models
llm
rag
mlops
gpu
performance-optimization
inference
scaling
python
fastapi
kubernetes
vm
vector-database
23 min
Leverage Kubernetes To Optimize the Utilization of Your AI Accelerators
MLOps World - MLOps World & Generative AI World 2024
Nathan Beach
accelerators
kubernetes
kubernetes-engine
ai
gpu
optimization
training
inference
workloads
resource-utilization
cloud-computing
32 min
Memory Optimizations for Machine Learning
MLOps World - MLOps World & Generative AI World 2024
Tejas Chopra
model-pruning
neural-networks
cpu
data-quantization
machine-learning
llm
memory-optimization
quantization
inference
deep-learning
transformer-models
gpu
35 min
RAG Hyperparameter Optimization: Translating a Traditional ML Design Pattern to RAG Applications
MLOps World - MLOps World & Generative AI World 2024
Niels Bantilan
hyperparameter-optimization
pipelines
traditional-ml
rag
llm
mlops
ai
generative-ai
inference
orchestration
data-quality
machine-learning
30 min
A Practical Guide to Efficient AI
MLOps World - MLOps World & Generative AI World 2024
Shelby Heinecke
ai
artificial-intelligence
machine-learning
llm
large-language-models
model-optimization
quantization
small-language-models
function-calling
prompt-engineering
inference
model-efficiency
31 min
How to Run Your Own LLMs, From Silicon to Service
MLOps World - MLOps World & Generative AI World 2024
Charles Frye
llms
large-language-models
mlops
machine-learning-operations
inference
gpu
quantization
tensorrt-llm
vllm
modal-labs
model-serving
ai-engineering
30 min
Building Composite LLM Systems
MLOps World - MLOps World & Generative AI World 2024
Urmish Thakker
llm
large-language-models
open-source
artificial-intelligence
machine-learning
ensemble-methods
model-specialization
nlp
generative-ai
mlops
inference
training
30 min
Building Multimodal LLMs for Product Taxonomy at Shopify
MLOps World - MLOps World & Generative AI World 2024
Kshetrajna Raghavan
llm
multimodal-llm
generative-ai
machine-learning
mlops
production-ml
shopify
product-taxonomy
data-modeling
computer-vision
natural-language-processing
image-classification
gcp
hugging-face
ray
sky-pilot
triton
inference
1
2
Next ›
Last »