How Do You Scale to Billions of Fine-Tuned LLMs
May 15, 2024
5 min
Free
cuda
batching
llm
large-language-models
fine-tuning
lora
inference
scalability
parameter-efficient-fine-tuning
gpu
mlops
ai
Description
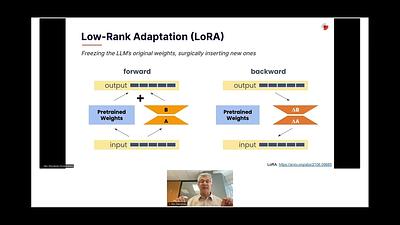
James Dborin of Titan ML discusses Batched LoRA Inference, a method that enables scaling to billions of personalized, fine-tuned LLMs without the prohibitive compute costs. The talk addresses the challenges of deploying numerous specialized LLMs and introduces how parameter-efficient fine-tuning techniques, combined with batching strategies, can allow multiple fine-tuned models to run in parallel on a single GPU. This approach significantly reduces costs and improves efficiency, akin to a CDN for LLMs.